K-Nearest Neighbors Method is used to classify the datasets into what is known as a K observation. The primary difference between cluster sampling and stratified sampling is that the clusters created in cluster sampling are heterogeneous whereas the.
Clustering In Machine Learning Geeksforgeeks
Clustering seeks to verify how data are similar or dissimilar among each other while classification focuses on determining datas classes or groups.

. 1 way you can combine both is by clustering your data using some interesting combination of features ahead of time lets say the combination is expensive to compute. 250 In general in classification you have a set of predefined classes and want to know which class a new object belongs to. This makes the clustering process more focused on boundary conditions and the classification analysis more complicated in the sense that it involves more stages.
Hierarchical clustering also known as hierarchical cluster analysis HCA is also a method of cluster analysis which seeks to build a hierarchy of clusters without having fixed number of cluster. Clustering finds the relationship between data points so they can be segmented. It is easy to recognize patterns as there can be a sudden change in the data given.
K-means clustering with k5 always performs better than with k4 if more than three attributes are considered. The two main types of classification are K-Means clustering and Hierarchical Clustering. It requires advance knowledge of K.
Top-down algorithms find an initial clustering in the full set of dimensions and evaluate the subspace of each cluster. We can conceptualize it in two dimensions by imagining it as a Cartesian plane. Analyticsvidhya knowm Attention reader.
The logistic Regression Method is used to predict the response variable. Hierarchical clustering has two different approaches Agglomerative and Divisive clustering. 21 Answers Sorted by.
We can see from the image above that the observations all lie within that feature space. A feature space is a space in which all observations in a dataset lie. The two main clustering methods are hierarchical clustering and k-means clustering.
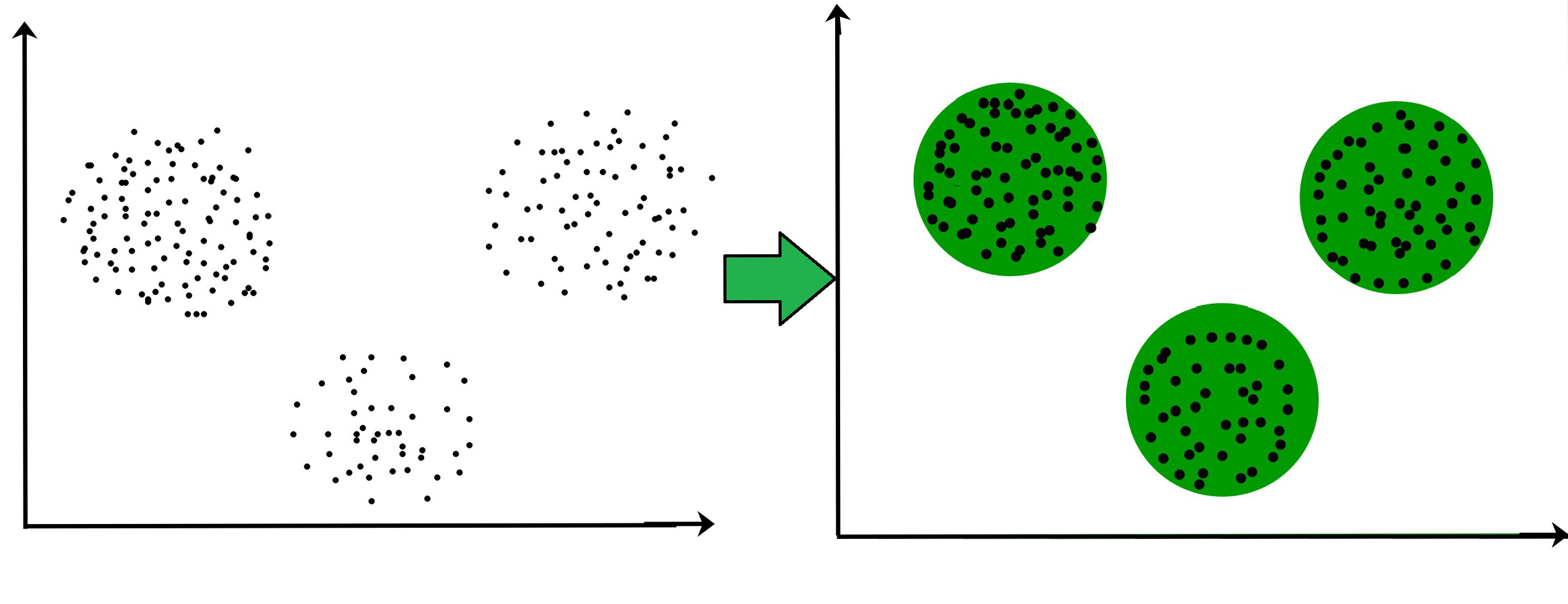
Clustering is unsupervised learning while Classification is a supervised learning technique. It groups similar instances on the basis of features whereas classification assign predefined tags to instances on the basis of features. Shorter the distance higher the similarity conversely longer the distance higher the dissimilarity.
There are two different types of clustering each divisible into two subsets Hierarchical clustering Agglomerative Divisive Partial clustering K-means Fuzzy c-means. They are unsupervised algorithms meaning that the data they are used with does not contain output labels. Clustering is the method of dividing objects into sets that are similar and dissimilar to the objects belonging to another set.
The goal of clustering algorithms is to group similar data points together. Agglomerative clustering also named bottom-up begins with assuming that all the data points are. In clustering the similarity between two objects is measured by the similarity function where the distance between those two object is measured.
In hierarchical clustering observation are sequentially grouped to create clusters based on distances between observations and distances between clusters. Clustering split the dataset into subsets to group the instances with similar features. The most simple way to understand clustering is to refer to it in terms of feature spaces.
K-Means is used when the number of classes is fixed while the latter is used for an unknown number of classes. Clustering Methods323 The commonly used Euclidean distance between two objects is achieved wheng 2. The methods include tracking patterns classification association outlier detection clustering regression and prediction.
K-means clustering is widely used in large data set applications. Giveng 1 the sum of absolute paraxial distances Manhat- tan metric is obtained and with g1one gets the greatest of the paraxial distances Chebychev metric. Distance is used to separate observations into different groups in clustering algorithms.
Clustering is an essential part of unsupervised machine. True In association rule mining the measure that shows the conditional probability that the consequent right hand side of a rule will occur given the antecedent left hand side of a rule is called. The main difference between them is that classification uses predefined classes in which objects are assigned while clustering identifies similarities between objects and groups them in such a way that objects in the same group are more similar to each other than those in other group.
My fictional analyst couldnt figure out why. We have collected and categorized the data based on different sections to be analyzed with the categories. Author Recent Posts gene Brown.
There are two branches of subspace clustering based on their search strategy. These cluster labels can then. Clustering tries to group a set of objects and find whether there is some relationship between the objects.
Another example of clustering there are two clusters named as mammal and reptile. In the following mock-up of a cluster model for my black-dress customers we see that many of the women purchased a dress in the first two months of the year and were in their early twenties. It is used to determine the similarities between the neighbours.
K-means is method of cluster analysis using a pre-specified no. The measurement unit used can affect the clustering analysis. The bottom-up approach finds dense region in low dimensional space then combine to form clusters.

The 5 Clustering Algorithms Data Scientists Need To Know By George Seif Towards Data Science

Clustering Algorithm An Overview Sciencedirect Topics
Exploring Clustering Algorithms Explanation And Use Cases Neptune Ai
.jpg)

0 Comments